
Introduction
Recruiting teams are drowning in applications. Average applications per job opening hit 257.6 in 2025, up from 207.2 the year before — roughly 50 more candidates per role, every role, every month. Manual screening at that volume isn't just slow; it's unreliable.
AI job matching has become the standard response. SHRM's 2025 Talent Trends report found 43% of organizations now use AI in HR tasks, up from 26% in 2024. That adoption curve is steep, and largely driven by necessity.
But "AI matching" has become a marketing umbrella covering everything from basic keyword filters to transformer-based semantic models. Most hiring teams can't tell the difference. That gap produces bad tool choices, wasted budget, and qualified candidates who never surface.
This guide breaks down exactly how AI matching algorithms work in practice — the technical pipeline, the meaningful differences between approaches, the real risks involved, and what actually separates a useful tool from an expensive shortcut.
TL;DR
- AI matching converts resumes and job descriptions into mathematical representations, then scores fit on skills, context, and career signals, not keyword overlap
- Technology has evolved from Boolean filters to transformer models achieving 89% F1 accuracy; graph neural networks add further structural gains on top of that
- Skills-based matching expands qualified candidate pools by 6.1x globally (15.9x in the US) compared to title-based filtering
- Bias enters through training data, proxy variables, and evaluation metrics — it's structural, not a minor edge case
- When evaluating AI matching tools, prioritize skills depth, explainability, bias controls, and ATS integration over database headcount
What Is AI Job Matching?
AI job matching is a technology system that analyzes candidate profiles and job requirements simultaneously, producing a ranked shortlist by identifying alignment across skills, experience, and role context. A recruiter no longer has to cross-reference criteria by hand.
The operational problem it solves is scale. At 250+ applications per role, human screening becomes inconsistent, fatigue-driven, and expensive. AI matching applies uniform criteria across every candidate, regardless of when they applied or how their resume is formatted.
The technology operates in two modes. Inbound matching screens candidates who apply to a posted role. Outbound matching proactively surfaces passive candidates from a broader talent pool before any application is submitted.
Obra Hire, for example, is built around outbound matching: hiring teams search 800M+ profiles using natural language or a pasted job description and get ranked, skill-matched results without waiting for applications to arrive.
That said, AI matching is not automatically objective. The algorithm reflects the data it was trained on and the criteria it was given. "AI" doesn't mean unbiased or infallible — which is why human review of match criteria remains an essential step, not an optional one.
How AI Job Matching Algorithms Work
AI matching operates as a pipeline. Raw, unstructured data enters one end; ranked candidates come out the other. Each stage either adds accuracy or introduces error, depending on the approach.
Input Parsing and Data Extraction
The process starts with NLP and Named Entity Recognition (NER) tools extracting structured information from free-form resume text : job titles, skills, certifications, tenure, and education. The same tools parse job descriptions for required qualifications, experience thresholds, and role context.
Parsing quality sets a ceiling on everything downstream. A resume the parser misreads produces a match score built on bad inputs.
Common failure points include:
- Non-standard layouts and creative formatting
- Abbreviated terms ("ML eng" vs. "machine learning engineer")
- Inconsistent date formats and employment gaps
- Skills buried in project descriptions rather than listed explicitly
Hybrid approaches combining rule-based systems with transformer models (SpaCy + BERT, for example) handle these variations more reliably than older rule-only parsers, but no parser is perfect, and the gap matters at scale.
Representation and Scoring
Once data is extracted, the system converts both the candidate profile and job description into vector embeddings (numerical representations in high-dimensional space where similar meanings cluster together mathematically).
This is how the system recognizes that "built data pipelines" and "data engineering experience" are semantically related without requiring identical phrasing. Scoring then works by comparing these vectors using cosine similarity or transformer-based methods, producing a composite fit score. Weighting logic typically applies factors like:
- Required vs. preferred skills (required skills carry more weight)
- Recency of experience (recent roles outweigh older ones)
- Proficiency level alignment
- Career trajectory signals
That weighting logic is usually proprietary and invisible to users, which creates real explainability problems — covered in the next section.
Feedback and Continuous Learning
Reinforcement learning closes the loop. Recruiter decisions (advancing a candidate, rejecting them, or making a hire) feed back into the model as training signals. Over time, the system learns which patterns correlate with successful hires for specific roles, teams, and contexts.
Tools with larger feedback datasets improve faster. A platform with millions of recruiter decisions has more signal to learn from than a niche tool with thin usage history. Scale here means better predictions over time, not just a bigger candidate pool.
The Evolution from Keyword Filters to Competency-Based Matching
Not every tool labeled "AI matching" uses the same underlying technology — and the generation gap translates directly into accuracy differences that affect which candidates you see and which you miss.
| Generation | Approach | Limitation |
|---|---|---|
| Gen 1 | Keyword/Boolean | Misses synonyms, context-blind |
| Gen 2 | NLP + skill taxonomies | Better recall, still title-dependent |
| Gen 3 | Word embeddings + semantic search | Understands meaning, not structure |
| Gen 4 | Transformer + GNN hybrid | Models relationships across labor market |
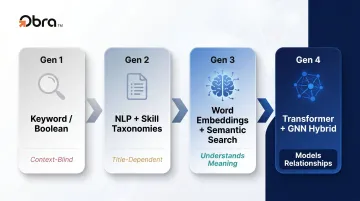
Many tools marketed as "AI" are running Gen 1 or Gen 2 logic. A dual-tower transformer semantic embedding model achieved 89.47% accuracy and an F1 score of 89.04% in resume-job matching — a benchmark Gen 1 keyword systems can't approach. Graph neural networks add another layer of structural improvement on top of that.
Semantic Matching vs. Keyword Matching
Keyword systems penalize candidates for using different-but-equivalent terminology. A candidate who writes "CRM tools" fails to match a job description requiring "Customer Relationship Management software" — even though they mean the same thing.
Semantic systems compare meaning, not strings. Skills-based matching extends this further by mapping extracted skills against structured taxonomies that capture relationships between skills, roles, and industries.
The Role of Skills Taxonomies
Standardized skills frameworks — like O*NET's taxonomy covering 1,016 occupations and 35 skill constructs — allow matching systems to recognize transferable skills across industries. A candidate with regulatory compliance experience in pharma may be a strong fit for a quality assurance manager role in medical devices, even without shared job titles.
The depth of a platform's skills taxonomy directly determines how well it identifies non-obvious but qualified candidates. Obra Hire's SkillsTree is a proprietary competency taxonomy covering 8,241 skills with proficiency levels — enabling competency-based matching that goes beyond title or keyword search.
Graph Neural Networks
GNNs represent the current frontier. Unlike document-level comparison, GNNs model the labor market as a connected graph: candidates, companies, skills, and job titles are all nodes linked by relationships.
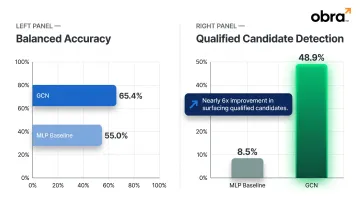
Research published in Data Science and Engineering (Frazzetto et al., 2025) compared GNN models against standard ML baselines on 8,360 candidates and 9,532 applications. Results:
- GCN achieved 65.4% balanced accuracy vs. 55.0% for MLP baseline
- Qualified candidate detection (minority class) jumped from 8.5% to 48.9% — nearly a 6x improvement
That second number is the one that matters. Surfacing qualified candidates whose profiles don't obviously fit a role is where flat models consistently fail — GNNs close that gap by modeling career trajectory and context, not just profile content.
Bias, Fake Candidates, and the Trust Gap
AI matching introduces two distinct challenges that don't solve each other: accuracy and trust. Both require deliberate design choices — not just better algorithms.
Where Bias Enters
Bias in AI matching isn't a bug — it's a structural feature of how these systems are trained:
- Training data bias: If historical hires skewed toward a particular demographic, the model replicates that pattern
- Proxy variable encoding: Zip codes, graduation years, and university names encode race, age, and socioeconomic status even when protected fields are explicitly excluded
- Evaluation metric bias: If "quality of hire" is measured at organizations with hostile cultures for underrepresented groups, the model learns to deprioritize those candidates
Research from the University of Washington published through the Brookings Institution (Wilson & Caliskan, 2025) tested LLMs on over 550 real-world resumes. The findings: LLMs preferred White-associated names over 85% of the time and male-associated names approximately 89% of the time when screening otherwise identical resumes.
Removing protected fields alone doesn't solve this. If proxy variables remain in the model inputs, the bias remains in the outputs.
The Fake Candidate Problem
The same AI tools improving matching quality are also being used by applicants to generate polished, keyword-optimized resumes that may misrepresent actual skills. Gartner projects that by 2028, 1 in 4 candidate profiles worldwide could be fake. Already, 39% of candidates report using AI during applications — 54% to generate resume text, 50% for cover letters.
This degrades matching inputs directly. Platforms responding to the problem — including Obra Hire's verified profile filtering on Explore and Scale plans — surface confirmed candidates and filter out synthetic ones before they reach the shortlist.
The Trust Gap
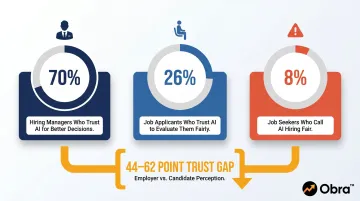
Fake profiles aren't the only source of friction. Employer confidence in AI hiring has climbed, but candidate trust hasn't followed — and the gap is wide:
| Group | Trust Level |
|---|---|
| Hiring managers who trust AI for better decisions | 70% |
| Job seekers who call AI hiring "fair" | 8% |
| Job applicants who trust AI to evaluate them fairly | 26% |
That 44–62 point gap has operational consequences. Candidates who don't trust the process disengage — and the most in-demand candidates, who have more options, disengage first. Explainability in matching tools isn't just an ethical consideration — it's a talent acquisition problem. Candidates who can see why they were matched or filtered are more likely to complete the process.
Responsible mitigation approaches include:
- Input anonymization before matching runs
- Adversarial debiasing during model training
- Regular third-party bias audits with published results
- Human review checkpoints before final decisions
- Verified profile filtering to address synthetic candidate fraud
What Hiring Teams Should Look for in an AI Matching Tool
Skills Depth vs. Database Size
A large candidate database with shallow matching logic surfaces many irrelevant results. A smaller database with competency-based matching surfaces more relevant ones. The better question to ask any vendor: not "how many profiles do you have?" but "how do you determine fit?"
Ask specifically whether the platform matches on skills graphs and proficiency levels, or just job title overlap. Obra Hire's freemium model lets teams preview candidate pool size and profile quality before spending any credits, so match relevance can be validated before committing budget.
Bias Controls and Explainability
Any AI matching tool used in hiring decisions should be able to answer:
- What signals drove this specific match?
- Has the model been tested for demographic bias?
- Is there an audit trail of decisions?
These aren't optional features. Four US jurisdictions now have active AI hiring regulations:
| Jurisdiction | Law | Key Requirements |
|---|---|---|
| New York City | Local Law 144 | Annual independent bias audit; public posting of results; candidate notification |
| California | FEHA Amendments (Oct 2025) | Anti-discrimination requirements; 4-year data retention; third-party vendor accountability |
| Illinois | HB 3773 (Jan 2026) | Mandatory candidate notification when AI is used in hiring |
| Colorado | Colorado AI Act (Feb 2026) | Risk management policies; annual impact assessments for employers 50+ |

Obra Hire's competency-based approach provides explainability through a clear breakdown of Must Have and Nice to Have criteria in every search result — showing exactly where each candidate matches or falls short.
Integration and Workflow Fit
The best matching algorithm delivers no value if the tool creates friction in daily recruiting. Look for:
- Broad ATS/HRIS integrations (Obra Hire connects to 85+ platforms including Workday, Greenhouse, iCIMS, Lever, and SAP SuccessFactors)
- Shared credit pools and centralized admin controls for team-wide use
- Fast onboarding with no contract or setup requirement
- Unlimited search on free tiers so teams can validate before paying
Frequently Asked Questions
What is the difference between keyword matching and AI-powered job matching?
Keyword matching counts exact term overlaps between resumes and job descriptions — so "CRM tools" fails to match "Customer Relationship Management software." AI matching converts both into mathematical representations to compare meaning, recognizing semantic equivalence without requiring identical phrasing.
How accurate is AI job matching compared to manual screening?
Accuracy depends on the algorithm generation. Transformer-based models now reach roughly 89% F1 scores, while graph neural networks improve qualified candidate detection by nearly 6x over flat ML baselines — though no system fully replaces recruiter judgment at the final decision stage. The gap over manual screening at scale is still significant.
Can AI job matching introduce or amplify hiring bias?
Yes — bias enters through training data, proxy variables (zip codes, graduation years), and evaluation metrics, and removing protected demographic fields alone doesn't solve it. Responsible tools combine adversarial debiasing, regular third-party audits, and input anonymization with human review checkpoints.
What data does AI use to determine candidate fit?
The system draws on extracted skills, job titles, tenure, education, certifications, and career trajectory patterns. Advanced systems also incorporate behavioral signals and feedback from past recruiter decisions, improving match quality over time.
How does skills-based matching differ from title-based matching?
Title-based matching filters by job title overlap, which excludes candidates who have the right skills but different titles. Skills-based matching maps extracted competencies against a structured taxonomy — LinkedIn's 2025 research shows this approach expands qualified talent pools by 6.1x globally and 15.9x in the United States.
What should hiring teams ask when evaluating an AI job matching tool?
Four questions matter most: Does it match on skills and competency depth, or just title overlap? Can it explain why a specific candidate was ranked? Is there filtering to remove AI-generated or unverified profiles? And does it integrate with your existing ATS without disrupting current workflows?


